Does Lawyering Matter? Predicting Judicial Decisions from Legal Briefs, and What That Means for Access to Justice
This study uses linguistic analysis and machine-learning techniques to predict summary judgment outcomes from the text of the briefs filed by parties in a matter. We test the predictive power of textual characteristics, stylistic features, and citation usage, and we find that citations to precedent—their frequency, their patterns, and their popularity in other briefs—are the most predictive of a summary judgment win. This finding suggests that good lawyering may boil down to good legal research. However, good legal research is expensive, and the primacy of citations in our models raises concerns about access to justice. Here, our citation-based models also suggest promising solutions. We propose a freely available, computationally enabled citation identification and brief bank tool, which would extend to all litigants the benefits of good lawyering and open up access to justice.
Introduction
Lawyers matter. Repeated studies have shown that represented parties achieve better civil litigation outcomes than their pro se counterparts, leading some to conclude that there can be no “meaningful access to justice” without access to lawyers.[1] In criminal cases, the Founders deemed a defendant’s right to counsel so important that they enshrined it in the Sixth Amendment, recognizing the need “to save innocent defendants from erroneous convictions.”[2] And in a decidedly more contemporary example, the development of artificially intelligent systems that can fight traffic tickets,[3] write and review contracts,[4] and provide legal advice,[5] has triggered a wave of dire predictions about the costs of a lawyerless justice system.[6]
But specifically, how and why lawyers matter is less clear.[7] Some scholars suggest that a lawyer’s mere presence in a case—regardless of his or her attributes, experience, or skill—signals to adversaries and the court that the case is meritorious.[8] Others argue that lawyers’ attributes, particularly their race, ethnicity, gender, and class, send even louder signals about their clients’ power and entitlement to a win.[9]
A different strand of the literature isolates and studies various aspects of lawyering, as distinct from the mere fact of a lawyer’s appearance in a case. A lawyer’s knowledge and use of various evidentiary procedures,[10] for example, as well as his or her previous experience[11] and “relational expertise” in a particular court,[12] have been shown to be positively correlated with successful client outcomes.
We add to this body of research by studying another aspect of lawyering: lawyers’ written advocacy to the courts in the form of legal briefs. The assumption that lawyers’ research and writing matters is legal education bedrock. Law students learn research and writing basics in their first year of law school and refine those skills throughout their legal education. Lawyers—and their clients—spend thousands of dollars on legal treatises and access to legal research databases such as LexisNexis and Westlaw. Continuing legal education courses serve to keep members of the bar up to date on recent case law developments. Collectively, these activities train lawyers in a set of norms and practices that are assumed to be the most effective for client advocacy. Yet, the effect of such training can be difficult to quantify, and the efficacy of conventional wisdom difficult to test.
In the present study, we use linguistic analysis and machine-learning techniques to mine the text of plaintiffs’ and defendants’ summary judgment briefs filed in 444 employment law cases in federal court. Through this analysis, we attempt to quantify the role that lawyers’ research and writing plays in influencing litigation outcomes. With respect to writing, we use textual characteristics, such as sentence length and brief length, along with stylistic features, such as the use of intensifiers (e.g., “obviously,” “clearly”), to predict the outcome of a motion for summary judgment. To measure the role of legal research, we test whether the number of citations, number of string citations, presence of specific important citations, and networks of citations across briefs can predict a judge’s decision. To establish a baseline for these experiments, we also review the body of legal research and writing (LRW) literature and form a set of hypotheses about which legal research and writing characteristics we would expect to be most and least effective.
Our results confirm some, though not all, of the conventional wisdom. The results generally support the advice from LRW scholars to convey the weight of the legal authority through comprehensive citations but to avoid lengthy string cites. Consistent with received wisdom, the results suggest that “positive intensifiers”—words like “precisely” or “fatal”—generally helped a brief. But contrary to received wisdom, so did “negative intensifiers” often associated with poor writing, such as “clearly” or “obviously”—although the effect was much weaker. And while LRW experts generally caution against excessively long sentences, our results found that average sentence length was not predictive of judicial outcomes.
However, the strongest results involved the citations themselves, suggesting that legal research plays a central role in brief writing. The presence of citations to particular cases in a brief boosted the performance of our predictive models. We also found that citing to cases commonly cited by other briefs in the sample tended to predict success, while citing idiosyncratic cases was a losing strategy. The most predictive model we tested involved grouping briefs according to common citations using network or graph analysis. We identified “neighborhoods” of winning briefs and could estimate a brief’s success based on the success of its case-citation neighbors. Collectively, these results suggest that legal research is one of the most important tasks a lawyer performs in motion practice: finding the right citations, in the right numbers, and presenting them effectively (rather than merely stringing them together) to the court.
While this result may seem unremarkable at first glance, citations’ importance in predicting summary judgment outcomes suggests a worrisome, yet depressingly familiar, story about access to justice. Resources matter, or more specifically, well-resourced lawyering matters. Choosing to include many citations, and choosing the right citations to include, requires access to Westlaw, LexisNexis, or other costly research databases. Even the Public Access to Court Electronic Records (PACER) system, the federal courts’ document access portal, offers only limited search capability and charges per page to download legal documents.[13] Other sources, like Google Scholar, offer free access to court decisions, but coverage is not comprehensive.[14] Further, research is time-intensive, and only well-resourced clients may be able to afford hours upon hours of lawyer time researching a brief. Lawyers at large firms also have access to extensive internal brief banks unavailable to self-represented parties and practitioners in legal aid organizations, solo practice, or small firms.
Nevertheless, our study also suggests a path to level the playing field. If access to court documents—both the parties’ briefs and the judges’ decisions—were universal and free, then methods like ours could be used to create an open access, computationally enabled brief bank or citation recommendation tool. Using network-analysis methods like the ones employed in this Essay, the bank could enable practitioners to “locate” their briefs in relation to sets of winning briefs in the same legal subfield and discover clusters of winning citations.
Such a tool would be particularly valuable for resource-strapped lawyers filing or responding to motions for summary judgment in areas with complex jurisprudence, bringing down the cost of legal representation and opening up access to justice. It could also serve as a decision-support tool for judges and their clerks, who could check whether parties omitted relevant case law commonly cited in other briefs. Lastly, tools of this sort could substantially reduce the transaction costs of motion practice, increasing the efficiency of the legal system.[15]
This Essay proceeds as follows: Part I provides a review of the extant text-analytics literature and an overview of the theoretical model underlying our approach. Part II presents an overview of our methodology, followed by the results in Part III. Finally, Part IV contextualizes the results, addresses access-to-justice implications, and describes our proposed computationally enabled brief bank solution.
I. Literature Review
This project falls within an emerging field of study known as computational legal studies, or legal analytics. Drawing from a variety of fields, including computational linguistics, computational social sciences, natural-language processing, computer science, and data science, computational legal scholars use advances in computing power and methods to analyze large, unstructured bodies of text to detect patterns and derive insight.
Text-analytic techniques have been applied to a wide variety of texts,[16] including legal documents. For example, law professor Nina Varsava examined judges’ writing style in a large set of opinions and found—contrary to conventional writing wisdom—that lengthy opinions written in a formal style were more likely to be cited by other judges than shorter, more readable opinions.[17]
Recent research has shown that decisions set forth in published opinions can often be predicted by machine-learning models trained on the texts of the statements of facts within those opinions.[18] However, critics of this work have observed that fact statements in published opinions are typically highly selective summaries of the original case record, written by the decision-makers themselves and tailored for consistency with the decision. Indeed, similar studies using documents drafted by self-represented litigants revealed that such documents are poor predictors of judicial outcomes.[19]
With respect to citations in particular, scholars have studied patterns in courts’ citations to precedent, tracing the ways in which citations “travel” across jurisdictions and years and identifying the most influential citation sets. The main focus of this work has been the U.S. Supreme Court’s and the U.S. Circuit Courts of Appeals’ use of and citation to Supreme Court decisions.[20] For example, Ian Carmichael and his coauthors used network analysis to discover that the Supreme Court tends to favor recent over older citations, and—perhaps contrary to intuition—shows no clear preference for citing unanimous opinions over those with concurrences and dissents.[21]
Text analytics can also serve as a window into lawyering practices as well as the underlying strategies of legal counsel. Political scientist Jessica Schoenherr constructed dictionaries of positive, neutral, and negative words that lawyers use in citing cases to analyze how lawyers use these cases in Supreme Court briefs.[22] Another study analyzed 318 closing arguments in tobacco litigation and found that tobacco companies made frequent reference to the plaintiff’s “decision” not to “quit smoking” despite “warnings” and “risks.”[23] Still another study examined terms of service contracts for “gig economy” companies and found that companies at higher risk of being sued for contract misclassification were more likely to include provisions intended to mitigate misclassification risk.[24] In other words, the presence of risk-mitigating language revealed the drafting lawyer’s underlying—and undisclosed—concern about litigation.
Even the length of text can be revealing.[25] In an analysis of internal corporate email at Enron, Eric Gilbert found that certain phrases and words tended to be associated with writing to subordinates, such as “have you been” or “I hope you.”[26] Other phrases were associated with writing to superiors, such as “attach,” and “thought you would.”[27] Psychology researcher James Pennebaker, who has written many influential articles and books on language use and social behavior, likewise found that those with high status in a group are less likely to use the words “I,” “me,” and “my” and more likely to use “we” or “you.”[28]
While legal scholars have devoted substantial attention to analyzing judicial opinions using text analytics—and to some extent oral argumentation—little attention has been paid to the text of legal briefs, where much of civil legal argumentation occurs. This is likely because of briefs’ relative inaccessibility, particularly in bulk. Major commercial legal research services like Westlaw, LexisNexis, and Bloomberg Law, to which most law faculty and students have free access, require each brief to be downloaded individually; the federal courts’ PACER system also requires individual, piecemeal downloads and charges ten cents per page.
Due to these barriers to accessibility, our study chose only one area of law—employment—and used law students to search for and download a random sample of all summary judgment decisions issued by U.S. district courts and the associated parties’ briefs in a ten-year period, 2007–2018. We then applied a variety of text analytics techniques to the brief-opinion sets for the purpose of predicting the outcome of the summary judgment motions.
Our approach draws upon the theoretical model shown in Figure 1. The model illustrates the range of factors that may influence outcomes in motion practice. A judge’s decision might be a function of the underlying merits of the case, as presented by the lawyers in their briefing (and to a lesser extent, in oral arguments). Our model also assumes that the outcome depends on the skill and resources of the lawyers who prepare the briefs. A skilled lawyer with time and access to legal databases, treatises, or brief banks containing relevant precedent (depicted in the model as “resources”), might enhance a client’s prospects through skillful argumentation, sufficient citations to legal precedent, useful portrayal and contextualizing of the legal precedent, or characterization of the facts in a manner that favors their client. Conversely, a lawyer who is inexperienced, hurried, a bad writer, or one with very limited access to legal databases and other resources, might impair their client’s chances through the brief they file with the court.
Figure 1: Theoretical Model Illustrating the Role of Lawyers, Judges,
and Underlying Merits in Legal Outcomes
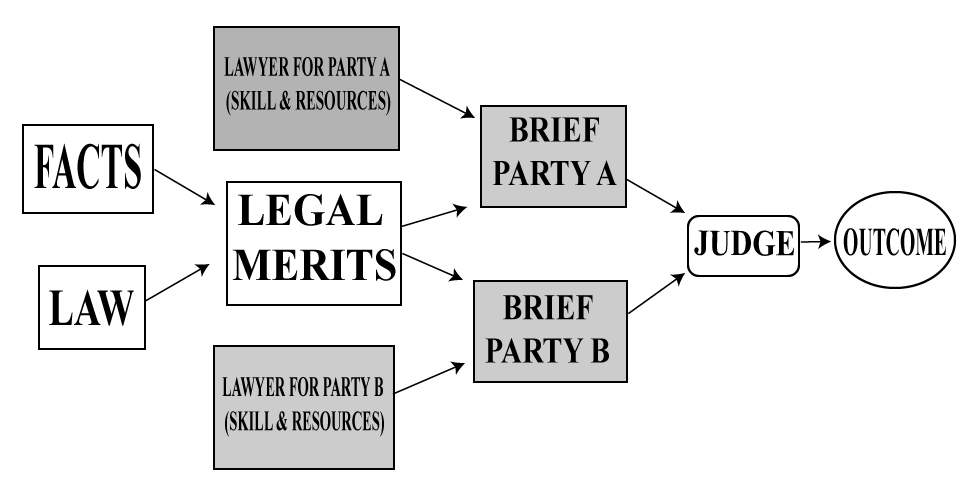
The theoretical model further reveals that it is difficult to disentangle legal merits from lawyering skills and resources through the analysis of legal texts. The language contained in a brief typically reflects both the underlying merits of the client’s case and whatever the lawyer adds or detracts from those merits (if anything at all). For example, the presence of many citations could signal strong legal merits, but it also could be attributable to the resources available to that lawyer, such as the luxury of time to conduct legal research or the availability of a large bank of similar briefs drafted by other lawyers at the firm.
The theoretical model also reveals the limits of our textual approach. The outcome—contained in an opinion written by the judge—reflects a combination of the judge’s judicial approach,[29] the underlying merits (revealed through the parties’ briefs), and whatever the lawyers add or detract through their briefs. However, our dataset does not include variables to account for a judge’s particular approach. Our model also does not account for structural factors that can affect the outcome, such as implicit or overt discrimination, access to legal counsel, or laws that systemically disfavor certain litigants or claims.
Our textual approach is further limited with respect to evaluating the efficacy of received wisdom with respect to legal research and writing. Most advice from legal research and writing scholars does not neatly translate into variables that can be measured through text analytics. For example, LRW scholars provide guidance about structuring the document as a whole, as well as the sequence of argumentation even within paragraphs (the familiar “IRAC” or “CREAC” construction of introduction, rule, application, and conclusion).[30] These dimensions of legal writing were too subtle to analyze using our methodology.
We were, however, able to test several lessons about effective research and writing mined from the LRW literature, which are summarized alongside the results section in Part III.
II. Methodology
A. Corpus
The Summary Judgment Corpus (SJC) that is the subject of our study consists of a random subset of cases involving summary judgment motions in 864 federal employment cases for the years 2007–2018.[31] Our team gathered the briefs and opinions via Bloomberg Law, which provides access to court documents via the federal courts’ PACER system.[32] Due to the resource-intensive nature of the document-gathering process, we selected only employment law cases (Tippett and Alexander’s substantive area of expertise). We identified these cases by using the following PACER “Nature of Suit” codes: “Civil Rights—employment,” “Labor—Fair Labor Standards Act” (FLSA), and “Labor—Family and Medical Leave” (FMLA).[33]
We chose to study summary judgment briefs and opinions because of their rich factual and legal content, and because the parties at this stage of litigation are incentivized to present their most effective, most thorough, and most skillfully argued positions. Summary judgment is a pivotal stage in a lawsuit, where a judge can dispose of a case in its entirety without trial.[34] Thus, summary judgment motions and their supporting briefs carry high stakes for litigants. One would, therefore, expect summary judgment research and writing—on both the moving and opposing sides—to be the best that the parties’ lawyers have to offer.
To assemble and prepare the SJC, a team of law students downloaded the target briefs and opinions, reviewed each opinion, and coded the outcome of the motion as granted in whole (win), denied in whole (loss), or granted in part and denied in part (partial). The “win” was characterized relative to the moving party, rather than to the plaintiff or defendant.[35]
The charts and tables below show the distribution of the 864 cases by year, “Nature of Suit” code, and judicial district, of which there are 94. Eighty-five districts are represented in the data set.
Figure 2: Distribution of Cases by Year
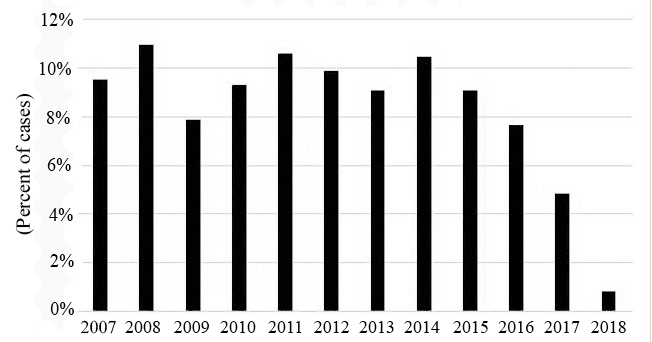
Table 1: Cases by Nature of Suit
| Nature of Suit | Percent of Cases in Data Set |
| Civil Rights – employment | 84% |
| FLSA | 12% |
| FMLA | 4% |
The experiments described here were limited to the 444 cases that included at least an initial brief and an opposition brief (including reply and surreply briefs, if any),[36] and in which the motion for summary judgment was either granted in full or denied in full. Motions that were granted in part and denied in part were excluded, as were cases in which the court ruled on cross-motions within a single opinion. While we could have incorporated these more complex decisions[37] into the machine-learning model, the output would have been more difficult to interpret. We, therefore, organized outcomes according to a binary “win/loss” assumption.
The exclusion of partial wins from the model alters the overall success rate of plaintiffs in summary judgment filings. Plaintiffs rarely file summary judgment motions, and when they do, they tend to target specific causes of action rather than the whole case. This is because the procedural posture of summary judgment strongly favors defendants.
Consider, for example, a religious harassment case under Title VII of the Civil Rights Act of 1964. For a plaintiff to prevail at trial, they would need to persuade a jury to believe their account of the facts as to each element of the case—that they suffered harassment based on their religion that was so severe or pervasive as to alter the terms and conditions of their employment.[38] However, for the plaintiff to prevail on summary judgment, they would need to show that the facts are so overwhelming as to be undisputed as to each element—in other words, that the employer has no facts to dispute the severity or pervasiveness of their harassment, nor the religious motivation for the harassment. If the plaintiff is asserting multiple causes of action, such as a separate claim for retaliatory firing in addition to harassment, they would need to show that there is no factual dispute as to each element of each cause of action in order win the entire case on summary judgment. Consequently, plaintiffs tend not to affirmatively move for summary judgment as to their entire case and may instead seek summary judgment on a single issue or cause of action.
By contrast, the defendant has a much easier burden when moving for summary judgment—the defendant must merely show that the facts are undisputed in the defendant’s favor as to a single element of the plaintiff’s claim. Because the plaintiff ultimately bears the burden of proof as to each element, a fatal defect in any one element of a cause of action justifies a summary judgment ruling in the defendant’s favor on that entire claim. For example, if the harassing conduct that the plaintiff alleges is insufficiently severe or pervasive to meet the legal standard for harassment based on similar cases, the court would grant summary judgment in the defendant’s favor on the harassment claim. Where the defendant is able to successfully challenge the sufficiency of the evidence as to at least one element for each of the plaintiff’s cause(s) of action, the defendant will prevail on summary judgment as to the entire case.
A corpus that excludes partial wins also tends to underestimate plaintiffs’ success at the summary judgment stage because a partial denial of a summary judgment motion brought by the defendant is a partial victory for the plaintiff. This means that the plaintiff will be able to proceed to trial, even with fewer causes of action. Likewise, a plaintiff who only wins in part on their own motion for summary judgment will still have a later opportunity to prove the remaining claims at trial.
Likewise, the exclusion of cross-motions that were decided in a single judicial opinion has a similar effect on results. The presence of cross-motions—where both the plaintiff and the defendant file motions for summary judgment—could signal that both sides believe they have a strong case. The outcome of such disputes may be different from those where only a single party files, which may indicate more lopsided merits, whether in the defendant’s or the plaintiff’s favor.
In summary, the absence of these partial results likely means that the corpus is skewed in favor of defendant-favorable legal cases and outcomes. This skew is visible in the summary statistics for the corpus. In 98% of the cases in this study, the defendant/employer filed the motion for summary judgment,[39] and 76% of those motions were granted.[40] This skew ultimately influenced the methodological approach we used in analyzing the data.
As described further below, many of our analyses used binary machine-learning classifiers. In simple terms, this means that we wrote computer code that “learned” from the textual, stylistic, and citation characteristics of a “training set” of winning and losing briefs and then applied that learning to classify a new “test set” of briefs as winners or losers.[41] How well the classifier did in guessing the correct outcome for the test cases supplies our measure of performance and gives us a window into which features of the briefs were most and least predictive of a summary judgment win.
Researchers have multiple options for measuring classification performance.[42] For example, researchers focused on identifying all positive instances (e.g., positive COVID diagnoses), even at the expense of generating some false positives, may choose to maximize a performance measure called sensitivity.[43] If the costs of a false positive are very high, however, then researchers might focus on another performance measure called specificity.[44] The changing medical advice about routine mammograms for all women at age 40 reflects a concern with false positives, as an abnormal mammogram may lead to costly, painful, stressful, and invasive follow-up medical procedures.[45] Other composite performance measures such as accuracy and the F1 score, or F-statistic, strike different balances between true and false positives and negatives.[46]
In our experimental results in the present study, we evaluate accuracy using yet another measure, the Matthews Correlation Coefficient (MCC).[47] This decision is driven by the substantial imbalance in our data set between granted summary judgment motions (positive instances) and denied summary judgment motions (negative instances). Widely used in machine learning applications in biostatistics, MCC is particularly useful where, as here, the underlying data is highly skewed. We also include the F1 score in the results presented below, as that measure may be more familiar to a computational legal studies readership. An MCC score of 1 is a perfect prediction of a positive relationship; a score of –1 is a perfect prediction of a negative, or inverse, relationship; 0 is a coin flip.[48] Our models, therefore, seek to maximize MCC score. As a starting point, we note that, due to the skew in our data, the MCC score for a model that predicts a brief’s chances of success based solely on whether the brief was filed by the movant or respondent is 0.481 and the frequency-weighted F-measure is 0.740.
B. Analytical Methods
After gathering our relevant brief-opinion sets, we performed several initial text processing tasks, including converting all text from its original .pdf or .docx format into machine-readable .txt format, parsing all text at the sentence level, and tagging all citations to case law within the text.[49] We then performed a series of analyses of citation usage, textual characteristics, and stylistic features of the text, assessing the briefs’ predictive power and testing the conventional wisdom of legal research and writing instruction.
We identified case law citations and string citations within briefs by building “finder” tools that searched for all combinations of numbers, punctuation, and characters that follow Bluebook citation formatting, aided by the list of citation and reporter formats provided by CourtListener.[50] Our analysis did not include citations to statutes, regulations, or the factual record, as such citations did not follow a standardized format, and varied considerably from brief to brief.[51] Parsing string citations to multiple cases, seriatum, proved particularly complex from a computational standpoint, due to the proliferation of periods, quotation marks, parentheses and other punctuation both within and between the citation itself, the parenthetical text, and the preceding sentences.
Separately, our analysis also classified individual citations according to the frequency with which they appeared in the corpus as a whole. This enabled us to differentiate between popular citations and those that appeared infrequently.
We also generated stylistic measures relating to legal writing, such as the use of negative intensifiers and positive intensifiers.[52] Stylistic measures were generated through the construction of custom style dictionaries through a close, qualitative review of a few dozen briefs in the original sample. Noteworthy word choices were grouped into categories and refined through further human review, with reference to the LRW literature. The dictionaries appear in the Appendix.
Our models also tested variables relating to the briefs’ textual characteristics—in particular, the number of documents filed (i.e., whether the parties filed a reply or surreply in addition to an opening brief); number of sentences in the brief; and average sentence length. Lastly, we included a set of control variables: court, nature of suit, and the parties’ pro se status.
III. Results
We begin with a discussion of the role of citations in summary judgment outcomes to better understand the role of legal research in good lawyering. We used multiple approaches to identify the use and efficacy of citations. First, we examined the role of the citation count per brief in predicting outcomes. Second, we tested the relationship between outcomes and the specific patterns of citations present in each brief. Finally, we used network analysis, also known as graph analysis, to identify case citations that were common among briefs in the corpus. This methodology allowed us to test whether outcomes for a brief could be predicted based on the success of briefs in the same “neighborhood,” or cluster, that cited to the same cases. We also used graph analysis to evaluate how well a brief connected to the larger body of case law within the corpus—was a brief citing many cases that were commonly cited by other briefs or was it citing to cases rarely cited by others?
We then attempted to understand the role of legal writing by testing the predictive power of various textual characteristics and stylistic features using machine-learning methodologies.
A. Citation Count
First, we modeled summary judgment wins[53] as a function of a variety of textual, stylistic, and citation-related features of the briefs. We discuss the textual and style-related results further below.[54] Our simplest approach to citation analysis was merely to count them: How many citations appeared per brief? These frequencies may serve as a rough proxy for the intensity of lawyering effort or the availability of lawyering resources. In a related analysis, we also counted the total number of documents filed in connection with each brief.
Summary judgment motion practice proceeds in multiple rounds, with an opening brief by the moving party, an opposition by the respondent, a reply by the movant, and an optional surreply (allowed at the judge’s discretion) by the respondent. Like citation frequency, the number of documents filed in connection with each brief might be an indication of the intensity of lawyering effort and/or available resources.
We found in our experiments that citation and document count, depending on the particular classification model and methodology employed, were consistently among the top predictive features of summary judgment outcome. We return to the implications of this finding in subsequent parts.
B. Citation Patterns
Beyond raw citation counts, we also performed a series of analyses based on which cases were cited and patterns of citations within the corpus. We first created citation frequency vectors that captured the number of times all citations appeared per brief.[55] For example, imagine that Brief B1 cited Case C1 twice, Case C2 once, and Case C3 twice. Brief B2 cited Case C1 zero times, Case C2 zero times, Case C3 three times, and Case C4 one time. The two briefs’ citation frequency vectors would look like the rows in Table 2:
Table 2: Illustration of Citation Frequency Vectors
| Brief | Citation Counts | |||
| Case C1 | Case C2 | Case C3 | Case C4 | |
| B1 | 2 | 1 | 2 | 0 |
| B2 | 0 | 0 | 3 | 1 |
Vectorizing citation frequency thus captures multiple dimensions of citation usage: the number of unique cases cited per brief, their frequency, and the overlap between briefs’ citation patterns.[56]
As Table 3 below shows, any given brief’s particular citation frequency vector was only modestly predictive of a summary judgment win. In other words, knowing the particular combination of cites present in a brief allows one to predict the brief’s success better than a coin flip, but only slightly. Citation frequency vectors were better at predicting whether a brief was filed by the plaintiff or defendant (MCC = 0.420, F1 = 0.690) and whether the brief was written by the movant or the respondent (MCC = 0.450, F1 = 0.694).[57] In other words, the cases parties cite depend on where they sit: plaintiffs tend to cite to a common set of cases, while defendants cite to their own common set of cases.
However, we also identified a subset of citations that, when present in a brief’s citation frequency vector, increased the probability of summary judgment win. We include the presence of the top 100 of these “information gain” citations in Table 3, associated with a near-tripling of the MCC score. Information gain here refers to the contribution of those particular features, or variables, to the predictive performance of the model.[58]
Table 3: Performance in Win/Loss Prediction Based on
Citation Frequency Vectors[59]
| Feature | MCC | F1 Score |
| Citation frequency vectors | 0.152 | 0.563 |
| The 100 highest information gain citations | 0.401 | 0.611 |
Interestingly, the top information gain cases were not exclusively, or even predominantly, U.S. Supreme Court cases. Instead, they appear to consist of circuit court cases that stand in for a particular type of fact pattern. This squares with intuition. Many, if not most, briefs that we reviewed contained boilerplate recitations of the summary judgment standard, citing civil procedure hornbook Supreme Court cases like Celotex Corp. v. Catrett.[60] Additionally, many briefs cited Supreme Court cases that establish the process for judicial analysis of the particular case type at hand, e.g., the burden shifting framework applicable to employment discrimination claims set out in McDonnell Douglas Corp. v. Green.[61] The popularity of these staple Supreme Court citations throughout the corpus means that their presence in any given brief would be unlikely to predict outcome.[62] Instead, the citations that were the most information-rich were cases from the country’s appellate courts.
By way of illustration, the top fifteen information gain cases are listed in Table 4 below.
Table 4: Most Predictive Cases in Corpus[63]
| Case Name |
| Elrod v. Sears, Roebuck & Co., 939 F.2d 1466 (11th Cir. 1991) |
| Hawkins v. Pepsico, 203 F.3d 274 (4th Cir. 2000) |
| Waldridge v. American Hoechst Corp., 24 F.3d 918 (7th Cir. 1994) |
| Causey v. Balog, 162 F.3d 795 (4th Cir. 1998) |
| Mendoza v. Borden, Inc., 195 F.3d 1238 (11th Cir. 1999) |
| Wascura v. City of South Miami, 257 F.3d 1238 (11th Cir. 2001) |
| Baldwin County Welcome Center v. Brown, 466 U.S. 147 (1984) |
| Knight v. Baptist Hospital of Miami, Inc., 330 F.3d 1313 (11th Cir. 2003) |
| Smith v. Lockheed–Martin Corp., 644 F.3d 1321 (11th Cir. 2011) |
| Bodenheimer v. PPG Industries, 5 F.3d 955 (5th Cir. 1993) |
| Lynn v. Deaconess Medical Center–West Campus, 160 F.3d 484 (8th Cir. 1998) |
| Rice–Lamar v. City of Ft. Lauderdale, 232 F.3d 836 (11th Cir. 2000) |
| Charbonnages de France v. Smith, 597 F.2d 406 (4th Cir. 1979) |
| Clemons v. Dougherty County, 684 F.2d 1365 (11th Cir. 1982) |
| Steger v. General Electric Co., 318 F.3d 1066 (11th Cir. 2003) |
| United Mine Workers v. Gibbs, 86 S. Ct. 1130 (1966) |
Notably, these cases are predominantly from the more conservative Eleventh and Fourth Circuits, and many were decided twenty or thirty years ago. The liberal Ninth Circuit does not appear on the list. Since our corpus was drawn from cases all over the country, this suggests that precedent from conservative circuits may be especially influential in summary judgment cases. This result may be partly attributable to the skewed nature of the corpus, which did not include the plaintiff-favorable partial rulings or cross motions decided in a single opinion.
Our review of these cases also suggests that almost all tended to stand for a very narrow set of facts and law that would justify disposing of a case on summary judgment.[64] For example, the case at the top of the list—Elrod v. Sears, Roebuck & Co.[65]—holds that an employer’s truly held belief that an employee engaged in harassment or retaliation can be a legitimate non-discriminatory basis for firing that individual, regardless of whether the harassment occurred.[66] The second case on the list—Hawkins v. PepsiCo[67]—holds that a personality conflict between a supervisor and a subordinate can be a legitimate non-discriminatory reason for a termination.[68] The third case—Waldridge v. American Hoechst[69]—involved a plaintiff who had submitted a bare-bones Statement of Genuine Issues that did not “identify with specificity what factual issues were disputed, let alone supply the requisite citations to the evidentiary record.”[70] This failure was a sufficient basis for granting summary judgment.
Nearly all of the top fifteen cases would have been helpful for an employer seeking summary judgment, which is unsurprising given the skewed nature of the corpus, in which employer-favorable rulings predominate. These cases tend to tip the balance in the employer’s favor, provided the employer can show that the facts of its own case are comparable to those in the cited case. Indeed, a case that cites Hawkins v. PepsiCo could suggest that the employer has a strong defense because the fact pattern resembles that in Hawkins. At the same time, a case that cites Hawkins may also be a mark of strong legal research, that the lawyer had sufficient command of the jurisprudence or resources and time to locate these narrow cases with factual parallels that favor their client’s case.
Only two Supreme Court cases appear on the list of the top fifteen most influential cases—Baldwin County Welcome Center v. Brown[71] and United Mine Workers v. Gibbs.[72] Both cases are somewhat obscure and are not commonly covered in employment law courses, nor do they contain boilerplate language on the summary judgment or burden shifting standards. This does not suggest, however, that lawyers should give up on citing Supreme Court jurisprudence. In a related finding in subpart III(C) below, briefs fared better when they cited to other cases commonly cited by others. This suggests that, while briefs should not only cite information-poor, commonly cited Supreme Court cases, neither should they cite only idiosyncratic, rarely used precedent. These results are discussed further below.
C. Graph Analysis
Our final exploration of citations’ predictive power employed graph analysis, also known as network analysis,[73] to illustrate and analyze shared citations among the network of briefs. This approach is similar to techniques used to map the citations among Supreme Court decisions over time,[74] and within statutes and regulations.[75]
Figure 3 below represents each brief as a gray circle and each cited case as a black circle. An “M” or “R” in a gray circle indicates whether the brief was filed by a movant or respondent on summary judgment.
Figure 3: Citation Graph Excerpt, Brief-Citation Network
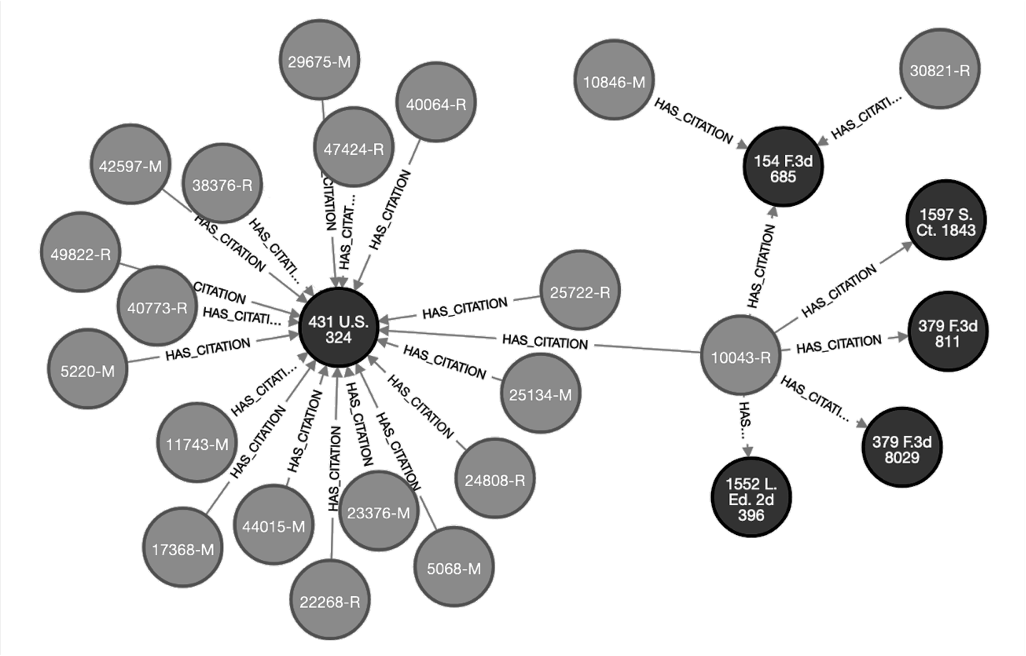
The citation graph provides a visual representation of commonly and less commonly cited precedent. In Figure 2, for example, many briefs cite to International Brotherhood of Teamsters v. United States[76] (the black circle in the middle), while only a few briefs cite to Hendricks-Robinson v. Excel Corporation.[77]
This network-based model enables us to make predictions about the probability of success of a particular brief, based on the frequency with which other briefs cite to the same precedent, and based on the success of those other citing briefs. A network-based model allows us to test two hypotheses. First, do briefs succeed by citing the same cases as other briefs, or by citing unusual cases not commonly cited by others? Second, this model allows us to test a predictive model that clusters cases together according to common citations. To the extent such clusters reflect common legal issues and common fact patterns, it might be possible to predict the success of a particular brief based on the success rates of other briefs within that cluster and nearby clusters.
For each brief in our graph, we derived the following predictive measures based on the characteristics of the citations within the brief and of other briefs that cite to the same cases:
Cluster Win Probability (M or R). The success rate of similar briefs, according to shared citations. Clusters include all briefs of the same type (movant or respondent) connected through a common citation. As illustrated in Figure 3, the value for this variable for brief 25722-R would average the win rate for all other “R” briefs within the Teamsters cluster.
Brief Cite Count. The number of citations in the brief.
Brief Cite Popularity. The popularity of each citation in a brief. In other words, the number of other briefs that cite to each citation in a brief.[78]
Opposing Party Shared Cites. The number of citations shared with the brief of the opposing party.
Brief Cite Win Score. The win rate of other briefs that cite to a particular case. This variable calculates the average “win score” for all citations in the brief.
Table 5 below shows the information gain—or relative contribution to the model’s predictive performance—from each of the graph features in win prediction. Entries of zero represent zero information gain. As Table 5 shows, the most predictive feature of the graph was Brief Cite Win Score, which captures the extent to which all cases cited in any given brief were also cited in other winning briefs. The next-most important graph features captured other aspects of shared-winningness: Cluster Win Probability (M or R). These variables measured the winningness of each brief’s network “neighborhood,” or cluster of briefs defined by the presence of at least one citation in common. Here again, the graph suggests that winning briefs share common citations, and that good lawyering, to some extent, may boil down to the ability to identify winning citations to precedent.
Table 5: Win Prediction Information Gain of Figure 3 Graph Features
| Graph Feature | MCC |
| Brief Cite Win Score | 0.207 |
| Cluster Win Probability (M or R) | 0.179 |
| Brief Cite Count | 0.035 |
| Opposing Party Shared Cites | 0.022 |
| Brief Cite Popularity | 0 |
Table 6, in turn, shows win prediction performance on the highest information gain features for combinations of the above listed variables. Here, we experimented with various combinations of graph features, and present the most predictive combinations for all briefs and for movants and respondents separately.
Table 6: Win Prediction Information Gain of Figure 3 Graph Features, Variable Combinations[79]
| Brief Type | Graph Features | MCC | F1 Score |
| All | Brief Cite Win Score, Opposing Party Shared Cites,
Cluster Win Probability (M or R), Brief Cite Counts |
0.477 | 0.742 |
| Respondent | Brief Cite Win Score, Opposing Party Shared Cites | 0.189 | 0.664 |
| Movant | Brief Cite Win Score, Opposing Party Shared Cites | 0.177 | 0.715 |
As Table 6 shows, the cumulative prediction rate for the most predictive group of network variables (MCC = 0.477), computed for all briefs (M and R), is comparable to the baseline prediction value based on party alone (MCC = 0.481). In other words, an algorithm that is blind to movant/respondent and plaintiff/defendant identifiers would be able to predict summary judgment outcomes with approximately the same success based on the various shared citation features generated by our graph analysis. This finding reinforces our earlier suggestion about the importance of research and citation selection among lawyering skills.
The “Respondent” and “Movant” rows in Table 6 offer more interesting insight. Here, the MCC values record the model’s success in predicting summary judgment outcomes above the baseline predictive power of party identity alone. The two variables that were most predictive, for both movants and respondents, were Brief Cite Win Score and Opposing Party Shared Cites.
This is particularly informative for respondents who, as noted above, tend to lose on summary judgment.[80] The graph analysis suggests that respondents whose citations mirror their opponents’ (movants’) citations, and whose citations also appear frequently in granted summary judgment briefs (i.e., the outcomes that are bad for respondents), tend to fare better on summary judgment. This highlights the value of defensive lawyering: respondents should not just make their own arguments, supported by their own sets of citations to respondent-favorable precedent. Instead, the analysis suggests that they should engage directly and substantially with the body of case law upon which their opponents rely.
Yet again, this strategy privileges lawyers and clients with sufficient time, staffing, and access to legal research resources to engage with their opponents’ citations and construct arguments in response. As discussed in greater detail in Part V below, these results suggest that network-based features could serve as useful predictors for the relative merits of a particular brief and could serve as the basis for an open-access computationally enabled brief bank or citation identifier to increase access to justice.
Our final set of analyses examined the degree of connectedness between citations in a given brief and the citations in other briefs. This method is similar to our approach illustrated in Figure 3 and Tables 5 and 6. However, rather than presenting briefs as “spokes” with common citations as “hubs,” Figure 4 below directly connects briefs to each other through shared citations, focusing on the many briefs that share citations with a single brief, 10043-R. For example, the moving brief “10846-M” (in the bottom left corner of the graph) shares one or more citations with 10043-R. Although the excerpt in Figure 4 is too small to reveal the extent of overlap in citations between 10846-M and other briefs, a brief with few spokes connecting it to other briefs would be more isolated within the network. The most isolated briefs had zero shared citations with other briefs (singletons). Only eleven briefs in the corpus were singletons.
Figure 4: Citation Graph Excerpt, Brief-Brief Network
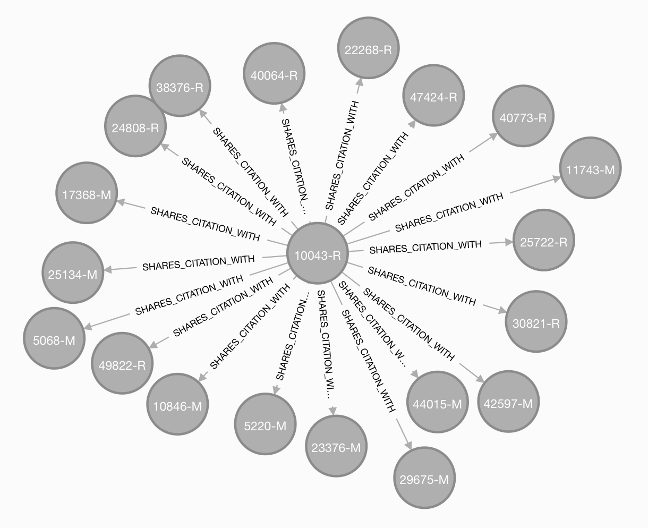
We then used this degree of shared citation measure as a predictor of summary judgment success. Notably, all of the singleton briefs with no shared cites were losing briefs. We visualize the probability of success based on shared citations in Figure 5, where the vertical axis captures a brief’s likelihood of success and the horizontal axis captures the number of other briefs having at least one citation in common with that brief. The upward slope of the line from left to right indicates a positive relationship between the two, such that the greater the number of shared citations, the greater that brief’s likelihood of success.
Figure 5: Mean Likelihood of Success as a Function of Shared Citations
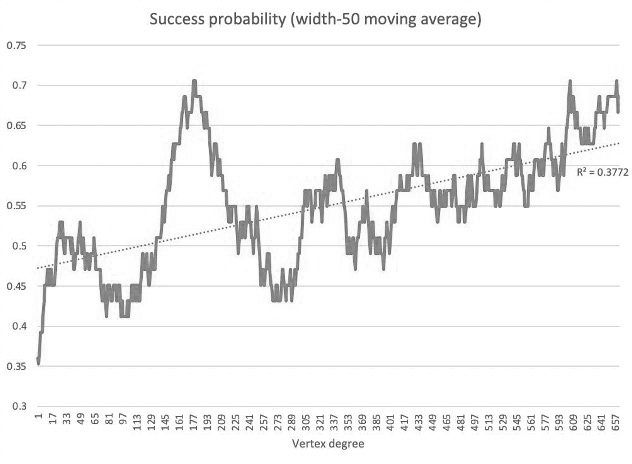
The relationship between success and vertex degree is particularly strong near the top of the scale—that is, the briefs citing many authorities that are cited by others. These results suggest, at the very least, that it is a poor strategy to exclusively cite unusual precedent in a brief, while those that cite to a common body of law tend to fare better. We return to the implications of these findings, and their connections to access to justice, further in Part V below.
D. Prediction from Textual Characteristics and Stylistic Features
We now move from legal research to legal writing. In addition to our analyses of citations as predictors of summary judgment outcomes, we tested the predictive effect of multiple textual characteristics, such as sentence count and length, and stylistic features, measured via the set of dictionaries available in the Appendix. Table 7 below lists the information gain of nine textual and stylistic variables. Note that the previously discussed party identity, document count, and citation count variables were more predictive than the features discussed here; the list shown in Table 7 picks up that set of features. Table 7 also omits the controls that we included in the model for court, case, and party characteristics, none of which improved predictive performance.
Table 7: Win Prediction Information Gain of Textual Characteristics
and Stylistic Features
| Feature | MCC |
| Hedging | 0.061 |
| Positive intensifiers | 0.056 |
| Sentence count | 0.056 |
| Negative intensifiers | 0.055 |
| Repetition | 0.046 |
| Total string cites | 0.044 |
| Mean string cite length | 0.032 |
| Mean sentence length | 0 |
| Negative emotional state | 0 |
In interpreting these results, we draw from the legal research and writing literature—that is, scholarship by law faculty who specialize in legal research and writing. These scholars serve as the source of received wisdom about effective legal writing. Throughout, however, we note the relatively greater importance of citations in predicting summary judgment outcomes—suggesting that regardless of a lawyer’s skill as a wordsmith, their skill as a researcher, or the research resources they have available, citations appear to be more important in securing a victory on summary judgment.
1. Hedging (e.g., “however,” “albeit,” “regardless,” “nevertheless,” “while”).—
Hedging was the most informative textual or stylistic feature in our analysis. Legal writing scholars devote substantial attention to the question of how best to handle problematic facts and case law. In general, they advise against ignoring bad law—indeed, lawyers have an ethical obligation to cite unfavorable controlling law.[81] Instead, they offer various strategies for handling bad facts, such as “address[ing] unfavorable facts more quickly and in less detail”[82] or “pairing that unfavorable fact with a more positive fact.”[83] Rocklin and her coauthors argue that unfavorable case law presents an opportunity for lawyers to “explain why, despite anything opposing counsel might say, you still win.”[84]
In our qualitative review, we observed that hedging words tended to be used when a lawyer was attempting to address a problematic aspect of the case by acknowledging the issue but noting the presence of a contrasting fact or legal authority. Thus, the presence of hedging words could signal skillful lawyering. This result also aligns with the graph analysis above, where respondents’ briefs that shared citations with movants’ briefs helped improve those briefs’ prospects. Taken together, these findings support the LRW advice to address bad or opposing legal propositions directly rather than merely stating one’s own affirmative case.
2. Positive Intensifiers (e.g., “conclusory,” “erratic,” “hastily,” “unmistakable,” “misplaced”).—
The presence of positive intensifiers in our corpus was also aligned with greater summary judgment success. We borrow the term “positive intensifier” from Beazley, who counsels using positive intensifiers instead of negative ones.[85] Beazley argues that positive intensifiers are distinct for their precision—that they are followed by more “concrete information” about what is wrong with the other side’s argument.[86]
Our dictionary of positive intensifiers does not exactly match Beazley’s, although there is some overlap. In our qualitative review, the use of positive intensifiers tended to be associated with high quality writing in a brief. While we were hard pressed to draw a clear distinction in meaning between negative and positive intensifiers identified in the LRW literature, we noted that positive intensifiers tended to be somewhat more muted. Thus, we classified the word “unmistakable” as a positive intensifier, though its meaning is not so different from the dreaded “clearly,” which, along with “obviously,” LRW texts advise strongly against. The positive intensifiers in our dictionary also tended to assign fewer negative attributes to the opposing lawyer or party (“misplaced” vs. “disingenuous,” “erroneous” vs. “illogical,” “obfuscate” vs. “cover up”).
It may be that the selective use of positive intensifiers, though hardly different in meaning from negative intensifiers, reflects a style of writing preferred by judges. It is also possible that positive intensifiers signal underlying merit. Lawyers who are confident of their case, for example, may feel no need to overstate and instead may use more muted language when the facts and law speak for themselves. Likewise, a lawyer who is truly confident about her case may feel no need to cast aspersions on the other side’s motives and may instead characterize the other side’s position as merely mistaken. Our modeling results confirm, though modestly, these propositions.
3. Sentence Count and Mean Length.—
Legal writing scholars provide nuanced advice with respect to length.[87] In the context of writing a statement of facts, for example, Rocklin and her coauthors note that the length should be driven by the complexity of the fact pattern.[88] Calleros, in his guidebook to legal writing, advises that writers “must strike an effective balance between light and in-depth analyses to achieve the dual goals of clarity and concision.”[89] Scholars encourage authors to strike a balance between low-level and complex analysis. While light analysis is often insufficient, “in-depth analysis . . . may cause the reader to grow weary and to lose sight of the general legal theory.”[90]
With respect to sentence length, Beazley suggests variety: “One short sentence can be effective. More than two short sentences are not.”[91] Rocklin advises editing with an eye toward “unwieldy” and “overly long” sentences” with “too many embedded ideas” or “too many empty words.”[92] McAlpin advises against sentences that are more than 25 words long.[93] Oates, Enquist, and Kunsch argue that sentence length depends on the reader and the context, but generally caution against “overly long sentence[s].”[94]
Our predictive models include two variables relating to length. We include a variable for the number of sentences within a brief—which was a proxy for the length of the brief as a whole. We also include a variable for the average length of sentences. While this variable would pick up briefs where lengthy sentences proliferate, it would not be able to detect the difference between a brief with average-length sentences and one with a mix of very short and very long sentences.
As Table 7 shows, the number of sentences per brief was approximately as predictive of a summary judgment win as the presence of positive intensifiers—that is to say, moderately so. Mean sentence length, on the other hand, produced no information gain, neither confirming nor disproving the LRW literature’s advice.
4. Negative Intensifiers (e.g., “frivolous,” “obviously,” “clearly,” “unfounded,” “whatsoever,” “woefully”).—
The term “negative intensifier” comes from LRW scholar Mary Beth Beazley[95] and refers to words that tend to overstate one’s case or denigrate the other side. Other legal writing scholars likewise advise against hyperbole—Rocklin advocates for “striv[ing] for a tone that suggests objectivity even while presenting the facts from your client’s perspective.”[96]
In our qualitative review of briefs, we observed a particular prevalence of negative intensifiers in briefs that were poorly written. We also observed that negative intensifiers tended to be used in personal attacks against the opposing side, a tactic that legal writing scholars discourage.[97] We, therefore, use negative intensifiers as a proxy for poor writing. At the same time, it is possible that the use of negative intensifiers could signal the underlying merits of a case in either direction. Lawyers might use extreme language when the facts are extreme. Alternatively, they might use extreme language to cover up factual gaps and weaknesses—a signal that these lawyers “doth protest too much.”[98]
Negative intensifiers may also affect outcomes independent of the merits. Such language may be particularly irksome to judges, who in one survey singled out the word “clearly” as a particular dislike in briefs.[99] Judicial irritation may thus have an independent effect on case outcomes.
Here, we observe that the presence of positive intensifiers is more heavily associated with summary judgment success than the presence of negative intensifiers, lending support to the weight of LRW advice. However, the difference between the information gain associated with the two intensifier types is small, suggesting that, on the whole, intensifiers are helpful, and positive intensifiers only slightly more so than negative.
5. Repetition (e.g., “again,” “also,” “many,” “repeatedly,” “both,” “neither”).—
Legal writing scholars take a nuanced position with respect to repetition in legal briefs. Oates, Enquist, and Kunsch, for example, note that “[i]n the United States legal culture, conciseness is even more highly prized as lawyers fight to keep their heads above the paper flood.”[100] However, they also note the usefulness of introductions, conclusions, and mini-conclusions—which serve as a form of repetition.[101] They also note the persuasive power of subtle repetition, using slightly different wording to reinforce a theme or theory of the case.[102]
We constructed the repetition dictionary to contain words that tended to preface a repeated reference to a particular fact or that served to highlight a pattern of conduct or related facts. We hypothesized that repetition words might signal a somewhat stronger case through related facts and legal arguments that support a trend. However, like intensifiers, the converse may be true—that the use of repetition words signals excess verbiage and mindless emphasis that could have been removed through more aggressive editing.
Our results place repetition words near the bottom with respect to information gain, suggesting that this particular lawyering strategy may only be marginally effective.
6. String Citations (total and mean length).—
String citations consist of multiple citations in a row, often with a parenthetical describing the relevant facts or legal proposition. Rocklin and her coauthors argue that string citations are useful for proving the presence of a legal trend.[103] However, they caution that string cites are “difficult to read” because they “create a long block of text” that “readers tend to skip over.”[104] They also note that string cites can be a waste of space if the cites relate to a generally accepted proposition of law.[105]
String cites do not have universal approval within the legal writing literature. Mary Beth Beazley cautions against string citations, arguing “[j]udges are almost uniformly against the use of string citations.”[106] Beazley also suggests that the parenthetical text separating string cites are fraught with peril, noting that “ineffective parentheticals tend to give the reader a snippet of information, but not enough to make the case useful to the reader.”[107] By contrast, Garner argues that string cites are “relatively harmless” once they have been moved to the footnotes.[108]
We include two variables relating to string cites in our predictive models. One variable counts the number of string cites, where each set of string cites counts as one cite. Another variable counts the average number of cited cases within a string cite to test the proposition that long string cites are generally unhelpful.
Our results suggest a saturation point: string cites themselves were helpful in predicting summary judgment wins, but only to a point. Confirming LRW advice, lengthy string cites containing five or more citations tended to detract from a brief’s prospects.
7. Negative Emotional State (e.g., “upset,” “scared,” “threatened,” “cried”).—
Rocklin and her coauthors advise lawyers to use “emotional facts” judiciously, characterizing them as “a kind of background that cause a reader to feel positively toward one party or negatively toward another.”[109]
The use of words describing an individual’s negative emotional state were relatively rare within the subsample of briefs used to generate the dictionaries. However, this negative-emotional-state language tended to appear in briefs describing particularly aggravated fact patterns. Although some of this usage could reflect rhetorical flourishes or exaggeration by lawyers, it may also signal the underlying merits of the dispute.
Here, our results showed no information gain from the inclusion of negative-emotional-state language, though our analysis could not distinguish between language that a reader might deem excessive or hyperbolic and language that accurately describes underlying fact patterns that themselves are quite negative or extreme.
8. Controls.—
Finally, we note that none of the control variables had a meaningful effect in our analyses. This finding was somewhat surprising, particularly with respect to the pro se variable, which we expected to be highly predictive of summary judgment losses. However, it is likely that the effect of pro se status—and in particular the resource disadvantages associated with pro se status—was captured through other variables. Pro se litigants, for example, may not cite to case law; know about filing reply briefs; or be exposed to the kind of legal-writing training that urges the use of positive identifiers.
In fact, all our style and citation variables were negatively correlated with pro se status, and the largest differences between pro se and represented parties were in the variables that capture aspects of citation usage. These findings align with our more general conclusion about the primacy of legal research in effective lawyering and highlight the need for open-access solutions like the one we propose in the Part that follows.
IV. Discussion
Broadly speaking, our results suggest that lawyering matters, and more intensive lawyering pays dividends. Filing additional briefs improves a client’s prospects, and longer briefs fare slightly better. More citations help, particularly where lawyers rely on a common set of cases widely cited by winning briefs. The results further suggest that merely dumping those citations into lengthy string cites does not help. Instead, careful framing of the law and facts through emphasizing the strong points (i.e., the use of positive intensifiers) and addressing weak points (i.e., hedging) makes a difference. In addition, thorough research that leads a lawyer to uncover a compelling case with similar facts (such as one of the highest “information gain” cases) could tip the scales toward a favorable outcome.
Notably, many of our findings parallel the results of a 2013 study by Professor Scott Moss of plaintiffs’ briefs filed in opposition to summary judgment in employment discrimination cases in which defendants asserted a particular defense—the “same actor” defense. There, Professor Moss reviewed 102 plaintiffs’ briefs and found that more than ten percent displayed “no research tailored to the case. . . [or] only one or very few on-point citations.”[110] On the basis of this and other observations, Professor Moss concluded that brief quality, including the quality of citations, was a good predictor of plaintiff loss on summary judgment.[111]
To be sure, some of the results of both our study and Professor Moss’s study could be traced to the underlying merits of the dispute.[112] As previously noted, lawyers may find it easier to use positive intensifiers when they have a strong case. A lawyer defending a company in an employment case may only be in the position to cite one of the top fifteen “information gain” cases if she has facts that line up with that case, which may furnish a strong defense on their own. And if an underlying case is strong, there may be more favorable case law to add to the brief.
In addition, the results are somewhat reflective of the imbalanced corpus, particularly the exclusion of motions that were only partially granted (an outcome that is generally favorable to the plaintiff). Most cases in the corpus were rulings in favor of the employer, meaning that the stylistic- and citation-based predictors of success were characteristic of the general approach that defense counsel tend to take in employment litigation.
Nevertheless, our results are in line with broader literature regarding access to justice. Our study suggests that clients benefit from well-resourced lawyers who can draw their citations from an array of treatises, legal databases, and even internal brief banks to copy and paste legal arguments from similar factual settings. By contrast, a pro se party or a harried plaintiffs’ lawyer, solo practitioner, or legal aid attorney with a large caseload may be limited in the results she can achieve if she lacks the time and resources to submit a well-researched surreply or to draft a comprehensive opposition brief that takes on the movant’s authority citation by citation. Limited access to legal databases or treatises means she might miss a helpful case or include fewer total citations.[113]
At the same time, our results suggest promising avenues for improving access to justice. In particular, the graph-analysis results suggest that it would be possible to create an open-access, computationally enabled brief bank or citation recommendation tool. Recall that the graph analysis enabled us to predict a brief’s prospects based on the success of other briefs that cited the same cases. Using similar methodology, it would be possible to radically reduce the amount of legal research needed to identify relevant citations in drafting a summary judgment brief at any stage of motion practice.
A plaintiff’s lawyer could, for example, scan a defendant’s opening summary judgment brief into the recommendation tool. The tool would extract the citations and analyze where they sit with respect to other briefs in the corpus. Through the use of graph analysis, the tool would identify the cases most commonly cited in opposition to those cited in the defendant’s brief, i.e., those cases that would be candidates for the plaintiff lawyer’s own opposition brief. The tool would then rank those opposition cites according to their “win rate”—that is, how often other briefs citing that case prevailed in opposing summary judgment. The tool could then provide a ranked list of cases to include in an opposition brief and a set of winning sample briefs.
More sophisticated versions of such a tool could recommend accompanying text based on arguments mined from other briefs, similar to the “how cited” function in Google Scholar.[114] Citations could also be grouped by their proximity in briefs or their proximity in networks, which would likely correspond to related legal topics. These groupings could then serve as a basis for automated brief building.
Beyond identifying strategically useful cases, such a tool could also identify the “bedrock” cases that are most frequently cited in a particular factual setting or for a particular legal proposition. Although these popular cases on their own would not provide much “information gain,” citation to a common foundation of case law favors a party’s prospects in the aggregate. Thus, a brief builder tool that notes the generic cases cited for similar cases of that sort, presented alongside the boilerplate language that typically accompanies those citations, could also be useful in leveling the playing field between well-resourced and less-resourced lawyers.
Citation recommendation tools already exist to some degree—for example, through the legal tech startup, Casetext. Although Casetext uses artificial intelligence to make citation recommendations, the algorithm appears to combine case information extracted from briefs with search terms from the lawyer.[115] It does not appear to make use of network or graph analysis, which also leverages win and loss information. Other legal startups have also attempted to use machine learning to enhance and simplify legal tasks; however, most efforts appear directed at automating the contracting process rather than brief writing.[116] Likewise, writing software such as Grammarly and Briefcatch tend to be focused on grammatical errors and readability.[117] Other software seeks to automate tasks that would normally be performed by a paralegal or legal assistant such as formatting citations, keyciting authority, or generating tables.[118] Harnessing the power of these sorts of solutions, but focusing that power on the resource-intensive task of citation identification, holds real promise for access to justice efforts.
However, and this is a major “however,” a free or low-cost access to justice tool of this sort would only be as robust as the corpus of text from which it draws its conclusions. While large private legal research companies such as Westlaw, LexisNexis, and Bloomberg Law, sitting on mountains of briefs and court opinions, could readily construct such a tool for their paying clients, no similar bulk corpus of court documents is freely available. As previously noted, the federal court document repository, PACER, is expensive to access, does not enable easy identification of the briefs that go with each judge’s opinion, and is not set up for bulk downloads of brief-opinion sets. State courts have no single equivalent system to PACER, and the public availability of trial-level state court documents in electronic form varies wildly by jurisdiction.[119] Likewise, although semi-public resources, such as Google Scholar, are useful for conducting searches, their terms of service do not permit data scraping. In other words, as is increasingly true across domains, access to data serves as the primary differentiator between established industry players and researchers or advocates attempting to create tools for public purposes.
We note that Congress periodically considers making PACER free, which would be a substantial step in the right direction, as a complete corpus of brief-opinion sets would then be available as the raw material for graph and other predictive analyses like those described in this Essay.[120] The federal judiciary has opposed these moves, largely on the ground that their budget would suffer from the lack of PACER fee revenues.[121] Yet underfunded courts should not build paywalls around court documents as a way to generate revenue, as those paywalls—as our research suggest—merely reinforce existing resource disparities and block low-resource litigants from accessing justice.
Finally, we acknowledge that, like any algorithmic approach to decision-making, such a tool could have the effect of further reinforcing the influence of old case law while creating a lag in adapting to new fact patterns, legal theories, and judicial interpretations.[122] Presumably, older—and in our case, employer-favorable—case law would continue to be recommended by the algorithm as “winning” citations, while newer case law would take additional time to become established within the dataset. The algorithm might further cement and reinforce the influence of problematic but “winning” case law, similar to the winner-take-all tendency of other recommendation algorithms in other contexts, such as Spotify.[123] Lawyers who rely exclusively on such an algorithm without performing additional research of their own would risk missing new case law entirely and further delay the introduction of new case law into the algorithm. Such a pattern might result in the “ossification” of areas of law that would otherwise grow and develop in our common law system, as well as less space for cause-driven test cases that are designed to push past the boundaries of existing precedent.[124] Nevertheless, the algorithm could be tweaked, for example, to highlight and accelerate the introduction of new case law by tagging such cases for lawyers as “new” or “trending.”
In sum, to answer the question posed by our title, lawyering appears to matter a great deal. The sort of lawyering that matters the most—skilled legal research and effective use of citations—is costly and may be out of reach to most litigants. Open access solutions like the one we propose here could go a long way to level the playing field, but only if we as a society recognize access to court documents and data, like access to a good lawyer, as a key component of access to justice.
Conclusion
Lawyering—and more to the point, intensive lawyering—can drive the results in summary judgment rulings. Both legal research and stylistic decisions play a measurable role in legal outcomes. Our methodology suggests that a brief’s citations can be used to forecast its prospects based on the success of other briefs sharing those citations. The same methodology could also be used to recommend citations, which could save substantial research time and serve to level the playing field between clients who can afford intensive lawyering and those who cannot. Such a tool, however, could
most easily be constructed by large private legal research companies that already have access to giant corpora of briefs and court rulings, and would likely charge a substantial premium for access. Leveling the playing field would require making open access to briefs and court decisions available throughout our justice system.
Appendix—Stylistic Dictionaries[125]
Hedging—albeit, although, assuming arguendo, belie, even after, even assuming, even if, even though, even without, for the sake of argument, hardly, however, in any event, in response to, in spite of, nevertheless, nonetheless, notwithstanding, of no moment, rather, regardless, undermine, while, with respect to, yet
Negative Intensifiers—abandon, absolute, absurd, artificial, axiomatic, baseless, blatant, boldly, bootstrap, clear, complete absence, completely, conclusively, cover up, cover-up, critically, defective, disingenuous, egregious, epitome, fabricated, false, flimsy, frivolous, futile, futility, illogical, impossible, improper, impugn, inflate, invalid, lack merit, let alone, manifest, mere, mystery, no effort, obvious, patently, plainly, salvage, sandbag, simply, speculative, stark, totally, transparent, unfounded, unquestionably, vain, whatsoever, without question, woefully
Positive Intensifiers—conclusory, critical, erratic, erroneous, even, excuse, fatal flaw, faulty, hastily, inadequate, inconsistencies, indisputably, irrelevant, littered, misplaced, misrepresentation, never, obfuscate, only, overwhelming, remotely, shred, unacceptably, uncorroborated, unmistakable, unsubstantiated, unsupported
Repetition—additional, again, all, already, also, always, both, commonly, consistently, continue, daily, each, ever, expectation, expected, finally, frequent, generally, kept, maintain, many, monthly, most of the time, neither, never, nor, normally, not only, numerous, on more than one occasion, ongoing, permanently, practice, predominantly, previous, prior, repeated, routine, same, second, several, sometimes, standard, still, third, times, twice, unrelenting, weekly, yet again, uniform
Negative Emotional State—upset, scared, threaten, afraid, cried, upsetting, ill, horrify, severe, unrelenting, fear/ed, frighten, distress, tired of, unhappy, concerned, uncomfortable, agitated
- .See, e.g., Victor D. Quintanilla, Rachel A. Allen & Edward R. Hirt, The Signaling Effect of Pro se Status, 42 L. & Soc. Inquiry 1091, 1091 (2017) (“By and large, pro se claimants fail to receive materially meaningful access to justice.”); see also Emily S. Taylor Poppe & Jeffrey J. Rachlinski, Do Lawyers Matter? The Effect of Legal Representation in Civil Disputes, 43 Pepp. L. Rev. 881, 885 (2016) (concluding that “lawyers benefit their clients” while summarizing “the findings of empirical research on the effect of legal representation in nine areas: juvenile cases, housing cases, administrative hearings, family law disputes, employment law litigation and arbitration, small claims cases, tax cases, bankruptcy filings, and tort claims”). ↑
- .US. Const. amend. VI; Akhil Reed Amar, Forward: The Document and the Doctrine, 114 Harv. L. Rev. 26, 68 (2000). Discussing the right to counsel granted by the Sixth Amendment, Amar observes:
The specific Sixth Amendment right to counsel, and the overall architecture of the Sixth Amendment more broadly, aimed to save innocent defendants from erroneous convictions and to promote a parity of courtroom rights between the defendant and the government. At the Founding, an indigent defendant was entitled to government-paid counsel—namely, the judge—but as the adversary system sharpened and criminal law and procedure became more intricate, separate counsel became necessary to redeem the Amendment’s promise and purpose.
Id. (internal citations omitted). ↑
- .See Khari Johnson, The DoNotPay Bot Has Beaten 160,000 Traffic Tickets—and Counting, Venture Beat (June 27, 2016, 2:51 PM), https://venturebeat.com/2016/06/27/donotpay-traffic-lawyer-bot/ [https://perma.cc/TR3M-KEL5] (describing a bot “made to challenge traffic tickets”). ↑
- .See Beverly Rich, How AI Is Changing Contracts, Harv. Bus. Rev. (Feb. 12, 2018), https://hbr.org/2018/02/how-ai-is-changing-contracts [https://perma.cc/Q4DP-6TUE] (“The use of AI contracting software has the potential to improve how all firms contract.”). ↑
- .Asa Fitch, Would You Trust a Lawyer Bot with Your Legal Needs?, Wall St. J.
(Aug. 20, 2020), https://www.wsj.com/articles/would-you-trust-a-lawyer-bot-with-your-legal-needs-11597068042 [https://perma.cc/C9UB-KUSK] (describing a “wave of tech startups” built for “allowing [users] to draft documents or pursue smaller-value disputes without shouldering the high costs of hiring a lawyer”). ↑ - .Robert Weber, Will the “Legal Singularity” Hollow out Law’s Normative Core?, 27 Mich. Tech. L. Rev. 97, 99–101 (2020); Thomas Hedger, Should We Turn the Law over to Robots?, The Atl., https://www.theatlantic.com/sponsored/vmware-2017/robolawyer/1539/ [https://perma.cc/
6VHW-342B]. ↑ - .Emily Ryo, Representing Immigrants: The Role of Lawyers in Immigration Bond Hearings, 52 L. & Soc’y Rev. 503, 509 (2018) (“The research on legal representation in civil proceedings has long acknowledged the challenges associated with identifying the causal effects of legal representation.”). Pinpointing how and why lawyers matter is key to figuring out the extent to which artificial intelligence can replace lawyers. ↑
- .Quintanilla, supra note 1, at 1116. ↑
- .Gary LaFree & Christine Rack, The Effects of Participants’ Ethnicity and Gender on Monetary Outcomes in Mediated and Adjudicated Civil Cases, 30 L. & Soc’y Rev. 767, 768 (1996); David B. Wilkins & G. Mitu Gulati, Why Are There so Few Black Lawyers in Corporate Law Firms? An Institutional Analysis, 84 Calif. L. Rev. 493, 496–97 (1996) (exploring the dearth of Black lawyers); Mary-Hunter McDonnell & Brayden G. King, Order in the Court: How Firm Status and Reputation Shape the Outcomes of Employment Discrimination Suits, 83 Am. Socio. Rev. 61, 62–63 (2018); Jeff E. Biddle & Daniel S. Hamermesh, Beauty, Productivity, and Discrimination: Lawyers’ Looks and Lucre, 16 J. Lab. Econ. 172, 173 (1998) (examining the effect of lawyers’ physical attractiveness on their success). ↑
- .Colleen F. Shanahan, Anna E. Carpenter & Alyx Mark, Lawyers, Power, and Strategic Expertise, 93 Denv. L. Rev. 469, 480, 489–92, 505, 508–10 (2016); Anna E. Carpenter, Alyx Mark & Colleen F. Shanahan, Trial and Error: Lawyers and Nonlawyer Advocates, 42 L. & Soc. Inquiry 1023, 1024, 1027–28, 1049–50 (2017); Ryo, supra note 7, at 505, 511, 522–23. ↑
- .John Szmer, Susan Johnson & Tammy Sarver, Does the Lawyer Matter? Influencing Outcomes on the Supreme Court of Canada, 41 L. & Soc’y Rev. 279, 279 (2007) (finding that in the Supreme Court of Canada, prior litigation experience and litigation team size predicted positive outcomes “even after controlling for party capability, issue area, and judicial policy preferences”). ↑
- .Carpenter, supra note 10, at 1023, 1027, 1029, 1050. ↑
- .Though judges’ decisions are supposed to be available free of charge via PACER, courts regularly fail to enable free access. Charlotte S. Alexander & Mohammad Javad Feizollahi, On Dragons, Caves, Teeth, and Claws: Legal Analytics and the Problem of Court Data Access, in Computational Legal Studies: The Promise and Challenge of Data-Driven Legal Research (manuscript at 1, 5) (Ryan Whalen ed., 2020). Further, though the federal courts sometimes make PACER access available free of charge for researchers, our fee waiver request in connection with this research was denied, forcing us to rely on private databases to assemble our corpus. ↑
- .Google Scholar does not include lower state court rulings. See How to Find Free Case Law Online, Libr. of Congress, https://guides.loc.gov/free-case-law/google-scholar [https://perma.cc/
85PV-ZAA9]. ↑ - .See Adam R. Pah, David L. Schwartz, Sarath Sanga, Zachary D. Clopton, Peter DiCola, Rachel Davis Mersey, Charlotte S. Alexander, Kristian J. Hammond & Luís A. Nunes Amaral, How to Build a More Open Justice System, 369 Sci. 134, 135 (2020). ↑
- .Yla R. Tausczik & James W. Pennebaker, The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods, 29 J. Language & Soc. Psych. 24, 25–26 (2010); James Pennebaker, Ryan Boyd, Kayla Jordan & Kate Blackburn, The Development and Psychometric Properties of LICW 2015, at 9–10 (2015). ↑
- .Nina Varsava, The Citable Opinion: A Quantitative Analysis of the Style and Impact of Judicial Decisions 32, 37, 41 (Univ. Wis. Legal Stud., Working Paper No. 1494, 2018). ↑
- .L. Karl Branting, Automating Judicial Document Analysis, 2017 Proc. of the Second Workshop on Auto. Semantic Analysis of Info. in Legal Texts 1, 2; Ilias Chalkidis, Ion Androutsopoulos & Nikolaos Aletras, Neural Legal Judgment Prediction in English, 2019 Proc. of the 57th Annual Meeting of the Ass’n for Computational Linguistics 4317, 4317; Octavia-Maria Sulea, Marcos Zampieri, Mihaela Vela & Josef van Genabith, Predicting the Law Area and Decisions of French Supreme Court Cases, 2017 Proc. of Recent Advances in Nat. Language Processing 716, 720; L. Karl Branting, Alexander Yeh, Brandy Weiss, Elizabeth Merkhofer & Bradford Brown, Inducing Predictive Models for Decision Support in Administrative Adjudication, reprinted in AI Approaches to the Complexity of Legal Systems (Ugo Pagallo, Monica Palmirani, Pompeu Casanovas, Giovanni Sartor & Serena Villata eds., 2018). ↑
- .L. Karl Branting, Carlos Balhana, Craig Pfeifer, John Aberdeen & Bradford Brown, Judges Are from Mars, Pro Se Litigants Are from Venus: Predicting Decisions from Lay Texts, in Legal Knowledge and Information Systems 215, 215–17 (Serena Villata, J. Harata & P. Kemen eds., 2020) (explaining how case metadata unrelated to the merits of the complaint appears to be slightly more predictive than such texts). ↑
- .Iain Carmichael, James Wudel, Michael Kim & James Jushchuk, Examining the Evolution of Legal Precedent Through Citation Network Analysis, 96 N.C. L. Rev. 227, 228 (2017); J.H. Fowler, Timothy R. Johnson, James F. Spriggs II, Sangick Jeon & Paul J. Wahlbeck, Network Analysis and the Law: Measuring the Legal Importance of Supreme Court Precedents, 15 Pol. Analysis 324, 325–26 (2007); Yonatan Lupu & James H. Fowler, Strategic Citations to Precedent on the U.S. Supreme Court, 42 J. Legal Stud. 151, 152 (2013); Ryan C. Black & James F. Spriggs II, The Citation and Depreciation of U.S. Supreme Court Precedent, 10 J. Empirical Legal Stud. 325, 327 (2013); James H. Fowler & Sangick Jeon, The Authority of Supreme Court Precedent, 30 Soc. Networks 16, 17 (2008). ↑
- .Carmichael, supra note 20, at 228, 236, 259–60. ↑
- .Jessica Ann Schoenherr, Attorneys, Merits Briefs, and U.S. Supreme Court Decision Making 4–5 (2020) (Ph.D. dissertation, Michigan State University) (ProQuest). ↑
- .Stephan Risi & Robert N. Proctor, Big Tobacco Focuses on the Facts to Hide the Truth: An Algorithmic Exploration of Courtroom Tropes and Taboos, 29 Tobacco Control 41, 43 (2019). ↑
- .Elizabeth Tippett, Using Contract Terms to Detect Underlying Litigation Risk: An Initial Proof of Concept, 20 Lewis & Clark L. Rev. 549, 551 (2016). ↑
- .See Allison Shontell, When Amazon Employees Receive These One-Character Emails
from Jeff Bezos, They Go into a Frenzy, Bus. Insider (Oct. 10, 2013, 6:38 PM), https://www.businessinsider.com/amazon-customer-service-and-jeff-bezos-emails-2013-10 [https://perma.cc/6AYY-XS5R] (describing Bezos’s practice of sending emails with a single
character: “?”). ↑ - .Eric Gilbert, Phrases That Signal Workplace Hierarchy, 2012 Proc. of the ACM 2012 Conf. on Comput. Supported Coop. Work 1037, 1042. ↑
- .Id. ↑
- .James Pennebaker, The Secret Life of Pronouns: What Our Words Say About Us 174 (2011). ↑
- .The political values or ideologies of judges may be factors in their approach to a case. Other factors might include their knowledge and expertise, implicit biases, and their personal, professional, and judicial experience. Legal commentators have devoted substantial scholarship to the idea that judges themselves influence the outcome of a case. See generally Lee Epstein & Jeffrey A. Segal, Advice and Consent: The Politics of Judicial Appointments (2005) (discussing the outcomes of today’s partisan judicial appointment process, including vacancies in the judiciary, nomination, and confirmation); Christopher Zorn & Jennifer Barnes Bowie, Ideological Influences on Decision Making in the Federal Judicial Hierarchy, 72 J. Pol. 1212 (2010) (taking an analytical, model-based approach to evaluating decision making in the federal judiciary). ↑
- .Charles R. Calleros, Legal Method and Writing 148 (6th ed. 2002) (laying out the commonly-used IRAC structure); Joan M. Rocklin, Robert B. Rocklin, Christine Coughlin & Sandy Patrick, An Advocate Persuades 124, 127 (2016) (discussing IRAC structure and breaking down the sequence of an analogical argument); Laurel Currie Oates, Anne Enquist & Kelly Kunsch, The Legal Writing Handbook: Analysis, Research, and Writing 588–89 (3d ed. 2002) (describing different paragraph “shapes,” which vary according to the presence, order, and frequency of “general statement[s]” and “specific support”). ↑
- .Our goal was to download briefs and motions for a random set of 1,500 cases. We selected that random set and then identified and dropped duplicates, reducing the data set to 1,478 cases. Our research assistants (RAs) then read through the docket sheet of each case and downloaded all available summary judgment briefs and opinions. In this process, the RAs identified that many of the 1,478 cases were not actually employment cases or did not actually contain a summary judgment motion despite mentioning “motion for summary judgment” on the docket. For example, a case might contain a docket entry that sets the filing deadline for a motion for summary judgment, but then the parties never actually filed a motion. After dropping these non-responsive cases, the data set consisted of 864 employment cases in which a motion for summary judgment was filed. ↑
- .Public Access to Court Electronic Documents, https://pacer.uscourts.gov/ [https://perma.cc/A8C9-M2TB]. ↑
- .These case types come from the federal courts’ Nature of Suit codes. The plaintiff must choose one to categorize his or her case types at the time the lawsuit is filed. Though there is variation due to plaintiffs’ different interpretation of the Nature of Suit codes’ coverage, Civil rights–employment tends to cover job discrimination on the basis of race, sex, national origin, color, and religion. The Fair Labor Standards Act code covers claims for unpaid minimum wages and overtime. The Family Medical Leave Act code pertains to litigation concerning employees’ right to leave from work to provide medical or child care for themselves or a family member. ↑
- .Fed. R. Civ. P. 56. ↑
- .For example, if the court grants the motion for summary judgment, the movant’s brief would be labeled a “win” and the respondent’s a “loss.” Conversely, if the court denies a motion for summary judgment, the respondent’s brief in opposition to the motion would be labeled a “win,” and the movant’s brief a “loss.” ↑
- .We count a case as “complete” even if it lacks a reply brief, so the sequence would be initial brief–opposition–opinion. We see some justification for this approach because in our manual review of briefs, we found that the arguments presented in replies tended to duplicate what the party had already raised in the initial/opening brief. Using this method, we have 604 complete cases, or 70%. ↑
- .For simplicity, we use the term “win” and “loss” to refer to whether a motion was granted (win) or denied (loss). Note, however, that where a defendant loses a motion for summary judgment, they do not lose the case. Instead, it proceeds to trial. ↑
- .See, e.g., Abramson v. William Paterson Coll. of N.J., 260 F.3d 265, 276–77 (3d Cir. 2001) (explaining that a plaintiff must demonstrate five elements to make out a prima facie case for a religiously hostile work environment). ↑
- .About 87% of initial briefs were filed by defendants, and the remainder by plaintiffs. Plaintiffs (employees) make up a somewhat higher proportion of movants overall (13% in the corpus of 864 cases), but they are overrepresented among cases where the judge partially granted the motion in part and denied it in part. Due to the procedural posture of motions for summary judgment, it is nearly impossible for the plaintiff in a case to win an entire case on summary judgment. ↑
- .For another analysis on rates of summary judgment motions, see generally Theodore Eisenberg & Charlotte Lanvers, Summary Judgment Rates over Time, Across Case Categories, and Across Districts: An Empirical Study of Three Large Federal Districts (Cornell L. Sch. Rsch. Paper No. 08-022, 2008). For an analysis on the causes and consequences of the increase in employment discrimination cases since Title VII went into effect, see generally John J. Donohue III & Peter Siegelman, The Changing Nature of Employment Discrimination Litigation, 43 Stan. L. Rev. 983 (1991). In 2010, Laura Beth Nielsen, Robert Nelson, and Ryon Lancaster took up this thread, analyzing a random sample of 1,672 employment discrimination lawsuits filed in seven federal district courts and terminated in the 1988–2003 period. Laura Beth Nielsen, Robert L. Nelson & Ryon Lancaster, Individual Justice or Collective Legal Mobilization? Employment Discrimination Litigation in the Post Civil Rights United States, 7 J. Empirical Legal Stud. 175, 181 (2010). This study found that over half of cases reached relatively low-dollar settlements and 40% of plaintiffs lost on dispositive motions or at trial, leading the authors to conclude that “employment discrimination litigation seldom yields a substantial award for plaintiffs and seldom provides systemic results.” Id. at 188, 196. The 2017 book, Rights on Trial, provides the most recent update, finding in a study of 1,788 employment discrimination cases filed in federal court between 1988 and 2003 that “[c]ontrary to media images of litigation delivering significant awards to a high percentage of plaintiffs, [the] data reveal a system that dismisses or summarily terminates a significant portion of cases or that offers small settlements without authoritative determinations of the validity of claims.” Ellen Berrey, Robert L. Nelson & Laura Beth Nielson, Rights on Trial: How Workplace Discrimination Law Perpetuates Inequality 55 (2017). ↑
- .Max Kuhn & Kjell Johnson, Applied Predictive Modeling 1–2 (2016) (noting that “machine learning,” depending on the field, is also called “‘artificial intelligence,’ ‘pattern recognition,’ ‘data mining,’ ‘predictive analytics,’ and ‘knowledge discovery,’” and defining this process as “developing a mathematical tool or model that generates an accurate prediction” as to the outcome or target variable of interest). ↑
- .Gareth James, Daniela Witten, Trevor Hastie & Robert Tibshirani, An Introduction to Statistical Learning with Applications in R 29 (2017) (“There is no free lunch in statistics: no one method dominates all others over all possible data sets. . . . Hence it is an important task to decide for any given set of data which method produces the best results.”). ↑
- .Kuhn & Johnson, supra note 41, at 256 (describing sensitivity). ↑
- .Id. ↑
- .Sandhya Pruthi, Mammogram Guidelines: What Are They?, Mayo Clinic (June 25,
2021), https://www.mayoclinic.org/tests-procedures/mammogram/expert-answers/mammogram-guidelines/faq-20057759 [https://perma.cc/77XY-UBQU] (“The main concern about mammograms for breast cancer screening is the chance of a false-positive result.”). ↑ - .James, supra note 42, at 75–78 (describing the F-statistic and prediction accuracy measures). ↑
- .The MCC estimates how well the model predicts the outcome, where 0.0 means no better than chance and 1.0 perfectly predicts every outcome. Sabri Boughorbel, Fethi Jarray & Mohammed El-Anbari, Optimal Classifier for Imbalanced Data Using Matthews Correlation Coefficient Metric, 12(6) PLOS ONE 1, 1, 6 (2017). ↑
- .Jonathan H. Choi, An Empirical Study of Statutory Interpretation in Tax Law, 95 N.Y.U. L. Rev. 363, 387–88 (2020) (describing MCC, F1, and accuracy measures of classifier performance). ↑
- .We used the SpaCy sentence segmentation tool to split the text into sentence-level units. Linguistic Features, SpaCy, https://spacy.io/usage/linguistic-features#sbd [https://perma.cc/9473-2956]. ↑
- .Citation Lookup Tool, Court Listener, https://www.courtlistener.com/c/ [https://perma.cc/FZR2-JSR2]. ↑
- .While lawyers, on the whole, complied with Bluebook formatting rules in their references to case law, lawyers appear to need a Bluebook refresher when it comes to statutory, regulatory, and factual record cites. This final category was especially varied, making it nearly impossible to track the frequency with which lawyers cited to the record, and which types of record citations they used (e.g., deposition versus interrogatory citations) to support their arguments. Capturing record citations would be a useful additional component to this research, as it may help unpack the relationship between lawyer research and writing and the underlying merits of the case. ↑
- .For a discussion of positive and negative intensifiers, see Mary Beth Beazley, A Practical Guide to Appellate Advocacy 164 (2002). ↑
- .See supra note 35 and accompanying text (discussing our use of the term “win”). ↑
- .See infra Table 7 (discussing textual and style-related results). ↑
- .Our citation extraction code did not capture repeat citations through the use of “Id.” as “Id.” is used interchangeably for case citations and citations to the factual record. The citation extractor also performed somewhat inconsistently as applied to short cites. Thus, our citation frequency vectors would only have captured a fraction of the number of times a particular case was cited within a particular brief. ↑
- .Our citation frequency vectors are essentially bag-of-citations vectors, much like bag-of-words vectors in natural language processing implementations. See Yoav Goldberg, Neural Network Methods in Natural Language Processing 69 (2017) (describing the “bag-of-words approach” as “[a] very common feature extraction procedure[] for sentences and documents”). ↑
- .Recall that these are to some extent one and the same—almost all moving parties in the corpus are defendants, and almost all respondents are plaintiffs. ↑
- .See Kuhn & Johnson, supra note 41, at 463–64, 468, 472 (discussing different methods of quantifying predictor relevance as part of the input variable filtering process, which “can be a critical step in creating an effective predictive model”). ↑
- .We tested the performance of multiple binary classification algorithms and achieved the best performance using a Support Vector Machine (SVM) classifier, using Sequential Minimal Optimization via the Weka implementation. See James, supra note 42, at 337 (describing Support Vector Machine classifiers). ↑
- .477 U.S. 317 (1986). ↑
- .411 U.S. 792, 802 (1973). ↑
- .In this way, Supreme Court citations in our corpus functioned much like “stop words” elsewhere in natural language processing. These words, like “and” and “the,” are so common as to be nearly information-free and substantively unhelpful. See Resources, Univ. Notre Dame (2021), https://sraf.nd.edu/textual-analysis/resources/#StopWords [https://perma.cc/DE5R-ZKJW] (“Stop words are generally words that are not considered to add information to the question at hand.”). ↑
- .Elrod v. Sears, Roebuck & Co., 939 F.2d 1466, 1468 (11th Cir. 1991) (reversing age discrimination verdict where the plaintiff had been fired for sexual harassment and retaliation); Hawkins v. PepsiCo, 203 F.3d 274, 282 (4th Cir. 2000) (holding that a personality conflict can serve as a legitimate non-discriminatory reason for termination); Waldridge v. Am. Hoechst Corp., 24 F.3d 918, 924 (7th Cir. 1994) (holding that plaintiff’s bare-bones Statement of Material Issues of Fact can be a basis for granting summary judgment for the defendant); Causey v. Balog, 162 F.3d 795, 803 (4th Cir. 1998) (holding that a thirteen-month interval is too long to give rise to an inference of causation in a retaliation claim); Mendoza v. Borden, Inc., 195 F.3d 1238, 1249 (11th Cir. 1999) (holding that ogling and one instance of physical contact insufficient to survive summary judgment on harassment claim); Wascura v. City of S. Mia., 257 F.3d 1238, 1248 (11th Cir. 2001) (holding that close temporal proximity between protected conduct and termination, taken alone, does not establish pretext); Baldwin Cnty. Welcome Ctr. v. Brown, 466 U.S. 147, 148 (1984) (ruling on a statute of limitations issue); Knight v. Baptist Hosp. of Mia., Inc., 330 F.3d 1313, 1316–17 (11th Cir. 2003) (prescribing bases for distinguishing employees who are similarly situated in terms of their misconduct and performance record); Smith v. Lockheed–Martin Corp., 644 F.3d 1321, 1323 (11th Cir. 2011) (issuing an employee-favored ruling on reverse discrimination case). ↑
- .But see Lynn v. Deaconness Med. Ctr.–W. Campus, 160 F.3d 484, 485 (8th Cir. 1998) (reversing summary judgment in gender discrimination case brought by registered nurse who was male); Clemons v. Dougherty Cnty., 684 F.2d 1365, 1366–67 (11th Cir. 1982) (reversing summary judgment on First Amendment claim by police officer); United Mine Workers v. Gibbs, 383 U.S. 715, 729 (1966) (holding that a district court did not err in exercising pendent jurisdiction). ↑
- .939 F.2d 1466 (11th Cir. 1991). ↑
- .Id. at 1470. ↑
- .203 F.3d 274 (4th Cir. 2000). ↑
- .Id. at 276. ↑
- .24 F.3d 918 (7th Cir. 1994). ↑
- .Id. at 922. ↑
- .466 U.S. 147 (1984) ↑
- .383 U.S. 715 (1966). ↑
- .We implemented graphs in Neo4j. ↑
- .Carmichael, supra note 20, at 228. ↑
- .Ryan Whalen, Legal Networks: The Promises and Challenges of Legal Network Analysis 2016 Mich. St. L. Rev. 539, 551–52 (2016). ↑
- . 431 U.S. 324 (1997). ↑
- . 154 F.3d 685 (7th Cir. 1998). ↑
- .In more technical terms, this refers to the mean vertex degree of a brief’s one-hop neighbors. ↑
- .Weka implementation of Multilevel Perceptron. ↑
- .See supra note 40 and accompanying text (discussing summary judgment rates in employment discrimination litigation). ↑
- .Model Rules of Pro. Conduct, 3.3 (Am. Bar. Ass’n 2020) (“A lawyer shall not knowingly . . . fail to disclose to the tribunal legal authority in the controlling jurisdiction known to the lawyer to be directly adverse to the position of the client and not disclosed by opposing counsel . . . .”). ↑
- .Rocklin, supra note 30, at 273; see also Calleros, supra note 30, at 370 (advising “placing helpful information in the main clause and relegating adverse information to a dependent subordinate clause”); Beazley, supra note 52, at 123 (advocating the “buddy system” for “bad facts”—“[t]ry to make sure that every bad fact that must be included in the statement is paired with a good fact that explains (or neutralizes) its presence.”). ↑
- .Rocklin, supra note 30, at 274. ↑
- .Id. at 172. ↑
- .Beazley, supra note 52, at 164. ↑
- .Id. ↑
- .Limits in terms of the length of a particular brief are set forth by the Court through local rules. See, e.g., N.D. Cal. Civ. R. 6-3(a), 6-3(b), 7-2(b), 7-3(a), 7-3(c) (setting forth page limits for various types of legal pleadings); E.D.N.Y. Civ. R. 37.3(c)–(d) (same). These rules only impose a maximum page number for briefs—counsel are free to make their brief shorter. ↑
- .Rocklin, supra note 30, at 278. ↑
- .Calleros, supra note 30, at 296. ↑
- .Id. ↑
- .Beazley, supra note 52, at 163. ↑
- .Rocklin, supra note 30, at 296. ↑
- .Megan McAlpin, Beyond the First Draft: Editing Strategies for Powerful Legal Writing 48 (2017). ↑
- .Oates, supra note 30, at 645. ↑
- .Beazley, supra note 52, at 164. ↑
- .Rocklin, supra note 30, at 269. ↑
- .Beazley, supra note 52, at 151 (“Another ‘persuasive’ tactic that usually fails is an attack on opposing counsel or the judges in the court(s) below.”). ↑
- .William Shakespeare, Hamlet act 3, sc. 2, l. 254. ↑
- .Bryan A. Garner, Legal Writing in Plain English: A Text with Exercises 170 (2d ed. 2013). ↑
- .Oates, supra note 30, at 923. ↑
- .Id. at 924. ↑
- .Id. ↑
- .Rocklin, supra note 30, at 213. ↑
- .Id. at 214. ↑
- .Id. ↑
- .Beazley, supra note 52, at 83. ↑
- .Id. at 70. ↑
- .Garner, supra note 99, at 97–98. ↑
- .Rocklin, supra note 30, at 257. ↑
- .Scott A. Moss, Bad Briefs, Bad Law, Bad Markets: Documenting the Poor Quality of Plaintiffs’ Briefs, Its Impact on the Law, and the Market Failure It Reflects, 63 Emory L.J. 59, 87 (2013). ↑
- .Id. at 90. ↑
- .As Professor Moss puts it, “Do bad writers lose on summary judgment because they write bad briefs or because, lacking legal acumen, they take bad cases that savvier lawyers reject?”
Id. at 92. ↑ - .Focusing specifically on plaintiffs’ lawyers, Professor Moss suggests another pair of reasons for ineffective citation usage in what he calls “bad briefs”: plaintiffs’ lawyers’ “ignorant optimism” and “profitable laziness.” Id. at 96. The first category includes inexperienced lawyers who may underestimate the complexity of employment discrimination law and fail to cite appropriate cases. Id. at 96–97. The second category describes lawyers who operate high-volume “settlement mills,” putting very little effort into each individual case and attempting to extract settlement at the earliest opportunity. As a result, lawyers of this type produce bad briefs with bad citations. Id. at 97–102. Our computationally driven proposal would assist lawyers in the first category who are new to a specialty like employment discrimination, thereby increasing access to justice by speeding new attorneys’ climb up the field’s learning curve. Our proposal would also benefit lawyers in Professor Moss’s “lazy” category by allowing them to write better briefs with the same (already apparently minimal) or lower effort. Though this may trigger moral hazard worries, obtaining better briefs from both sides—regardless of the lawyers’ true level of laziness—undoubtedly improves the quality of the courts’ summary judgment adjudication. ↑
- .E.g., “How Cited” Results for Faragher v. Boca Raton, 524 U.S. 775 (1998), Google Scholar, https://scholar.google.com/scholar_case?about=15103611360542350644&q=faragher
+v.+boca+raton&hl=en&as_sdt=6,38 [https://perma.cc/7TCP-62N7]. ↑ - .Have CARA A.I. Find You the Most On-Point Authorities, Casetext, https://
casetext.com/cara-ai/ [https://perma.cc/GHC7-DHW5]. ↑ - .See, e.g., Stanford Law School: Codex Techindex, http://techindex.law.stanford
.edu/companies?category=3 [https://perma.cc/93PT-2MQJ] (offering mostly form and contract-related services); Westlaw Form Builder, Thomson Reuters, https://legal.thomsonreuters.com/
en/products/form-builder [https://perma.cc/Z5KF-HUA6] (offering to “[s]implify the form building process”). ↑ - .BriefCatch, https://briefcatch.com/ [https://perma.cc/Q2CH-HMB5]; Grammarly, https://www.grammarly.com/ [https://perma.cc/BY5U-7X3R]. ↑
- .E.g., Drafting Assistant for Litigation Documents, Thompson Reuters, https://legal.thomsonreuters.com/en/products/drafting-assistant/litigation [https://perma.cc/9JCN-RPGX]; Legal Brief Generator Software, Bundledocs, https://www.bundledocs.com/blog/2012/6/28/
legal-brief-generator-software.html [https://perma.cc/P6XM-MQSY]. ↑ - .Alexander & Feizollahi, supra note 13, at 2–3. ↑
- .Jacqueline Thomsen, Rejecting Opposition from Judiciary, House Passes Bill to Make PACER Free, The Nat’l L.J. (Dec. 8, 2020), https://www.law.com/nationallawjournal/2020/12/
08/rejecting-opposition-from-judiciary-house-passes-bill-to-make-pacer-free/ [https://perma.cc/
5GH4-Q3R4]. ↑ - .Id. ↑
- .The self-reinforcing nature of predictive analytics is well documented. See, e.g., Cathy O’Neil, Weapons of Math Destruction 7, 13 (2016) (arguing that large-scale mathematic systems are self-perpetuating feedback loops with the potential to cause serious social harm); Pauline T. Kim, Data-Driven Discrimination at Work, 58 Wm. & Mary L. Rev. 857, 895–96 (2017) (explaining that “feedback effects may cause biased models to become more accurate over time—the model in effect becoming a self-fulfilling prophecy”); Charlotte S. Alexander & Elizabeth Tippett, The Hacking of Employment Law, 82 Mo. L. Rev. 973, 993 (2017) (stating that “algorithms are not in the business of looking for new pathways to success; they identify and entrench existing ones instead”). ↑
- .See, e.g., Alan Krueger, Rockonomics 94 (2019) (explaining that “the rapidly growing set of curated recommendation systems that use Big Data to help us discover new music is also likely to reinforce network effects”). ↑
- .See, e.g., Cynthia L. Estlund, The Ossification of American Labor Law, 102 Colum. L. Rev. 1527, 1530, 1532 (2002) (warning that labor law, cut off from the “creative pressure of private litigation,” risks becoming “moribund” and ineffective). ↑
- .We included various suffixes, such as “-ly,” “-ed,” “-s,” and “-ing,” to the words in the dictionary. ↑